Lifecycle of the Event Loop
Explanation of how Node.js / Browser Event Loop works
S
A lifelong learner. Love to travel. Listen to music.
Search for a command to run...
Explanation of how Node.js / Browser Event Loop works
A lifelong learner. Love to travel. Listen to music.
No comments yet. Be the first to comment.
Originally posted in iXora Solution Blog In an ideal world, everything works successfully. However in real worlds there always unexpected errors. For example, a connection to the database drops out for whatever reason. So as a best practice, develop...
Best Practices for Path Structure, Versioning, and Error Handling

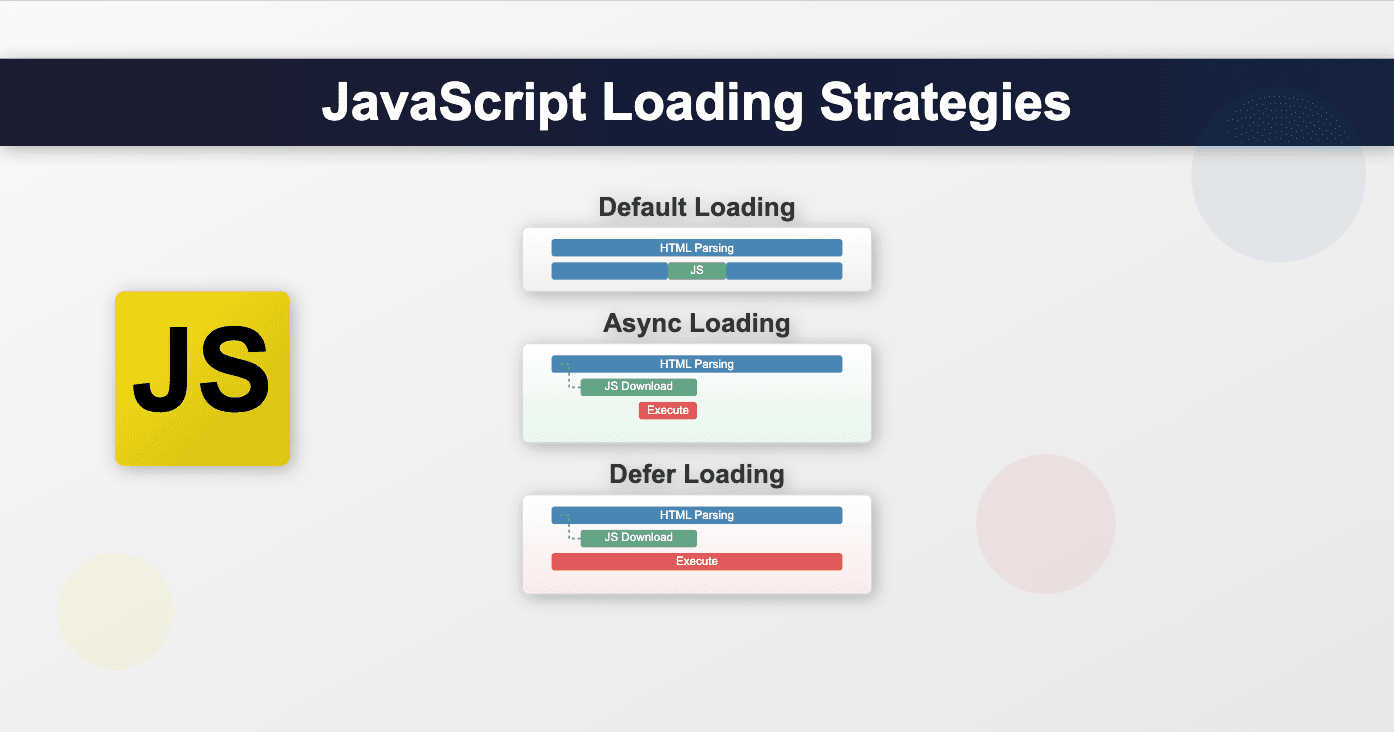
Understanding the Performance Implications of async and defer Attributes
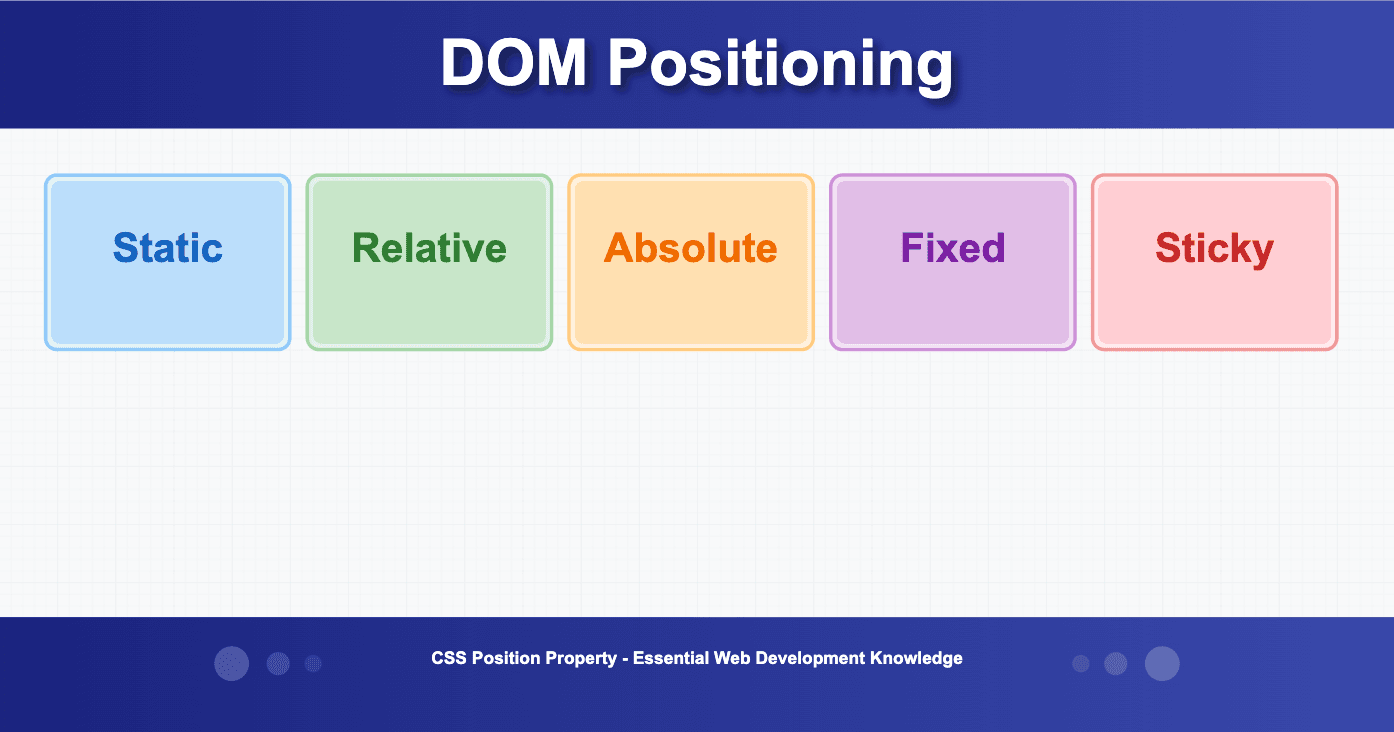
Overview static: Default position. It does not allow setting properties like top, bottom, left, right, z-index relative: Acts the same as static. but allows positioning it relatively by putting properties like top, bottom, left, right, z-index absolu...
Overview When an element in the browser has a conflict of styles, the browser uses a set of rules to determine which style should be rendered. This set of rules is defined as CSS Selector Specificity. For instance, for an element, if we have the foll...

Master block, inline, flex, and grid to build better web layouts

Node.js is used to build highly scalable server-side applications using JavaScript. It provides,
Event-driven
Non-blocking (asynchronous) I/O
Cross-platform runtime environment
The event loop is the core player for maintaining these properties and makes Node.js a faster runtime.
Anytime we run a node.js program, it creates one thread and then runs all of our codes inside that thread.
The event loop acts as a control structure to decide, what our one thread should be doing at one given time.
When we run a js file, Node first takes all the codes and executes them. This is the moment we enter the event loop.
Every time the event loop executes a cycle, in the Node.js world, it is called a tick.
Every time the event loop is about to execute, Node quickly checks whether the loop should proceed or not, for another iteration. If node decides not to run more iterations, the program closes and we go back to the terminal.
The event loop continues to the next iteration when shouldContinue method returns true.
When node goes through the code first time, it detects pendingTimers, pendingOSTasks, and pendingOperations.
Every single iteration of an event loop is called a tick. In pseudo-code, it looks as follows
// javascript code is written inside the myFile.js
const pendingTimers = [];
const pendingOSTasks = [];
const pendingOperations = [];
// New timers, tasks, and operations are recorded from myFile
myFile.runContents();
function shouldContinue() {
// Check one: Any pending setTimeout, setInterval, setImmediate?
// Check two: Any pending OS tasks?
// Like server listening to port, network calls
// Check three: Any pending long-running operation?
// Like fs module, thread pools tasks)
return (
pendingTimers.length
|| pendingOSTasks.length
|| pendingOperations.length
);
}
// Entire body executes in one 'tick'
while (shouldContinue()) {
// 1) Node looks at pending timers and sees if any
// functions are ready to be called (setTimeout, setInterval)
// 2) Node looks at pendingOSTasks and pendingOperations
// and calls relevant callbacks
// 3) Node pause the execution until,
// - a pendingOSTasks is done
// - a pendingOperation is done
// - a timer is about to complete
// 4) Look at pendingTimers. Call any setImmediate
// (This time node does not care about setTimeout or setInterval,
// it only looks at those functions, registered with setImmediate)
// 5) Handle any 'close' events
}
The event loop is concept within the JavaScript runtime environment regarding how asynchronous operations are executed within JavaScript engines. It works as such:
The JavaScript engine starts executing scripts, placing synchronous operations on the call stack.
When an asynchronous operation is encountered (e.g., setTimeout(), HTTP request), it is offloaded to the respective Web API or Node.js API to handle the operation in the background.
Once the asynchronous operation completes, its callback function is placed in the respective queues – task queues (also known as macrotask queues / callback queues) or microtask queues. We will refer to "task queue" as "macrotask queue" from here on to better differentiate from the microtask queue.
The event loop continuously monitors the call stack and executes items on the call stack. If/when the call stack is empty:
Microtask queue is processed. Microtasks include promise callbacks (then, catch, finally), MutationObserver callbacks, and calls to queueMicrotask(). The event loop takes the first callback from the microtask queue and pushes it to the call stack for execution. This repeats until the microtask queue is empty.
Macrotask queue is processed. Macrotasks include web APIs like setTimeout(), HTTP requests, user interface event handlers like clicks, scrolls, etc. The event loop dequeues the first callback from the macrotask queue and pushes it onto the call stack for execution. However, after a macrotask queue callback is processed, the event loop does not proceed with the next macrotask yet! The event loop first checks the microtask queue. Checking the microtask queue is necessary as microtasks have higher priority than macrotask queue callbacks. The macrotask queue callback that was just executed could have added more microtasks!
If the microtask queue is non-empty, process them as per the previous step.
If the microtask queue is empty, the next macrotask queue callback is processed. This repeats until the macrotask queue is empty.
This process continues indefinitely, allowing the JavaScript engine to handle both synchronous and asynchronous operations efficiently without blocking the call stack.
In summary, the Node.js event loop,
Process and execute code in index.js
Look for pending timers, OS tasks, and pending operations. If no tasks exist, exit.
Run setTimeout's, setInterval's
Run callbacks for OS tasks and thread pools pending stuff
Pause and wait for stuff done
Run setImmediate functions
Handle close events
Return to step 2
References:
JavaScript Visualized - Event Loop, Web APIs, (Micro)task Queue
Accompanying blog post by Lydia Hallie
In the Loop by Jake Archibald
What the heck is the event loop anyway? by Philip Robert
Handling MicroTask and MacroTask